
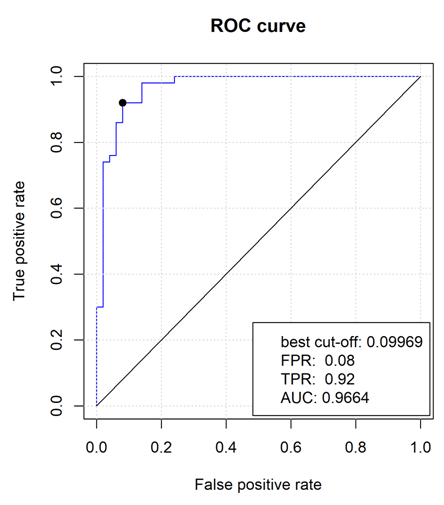

選用了目前主流的分類器(比如 SVM,KNN)以及篩選特征值的方法(貪婪算法)篩選并建立穩定的模型,幫助客戶篩選到靈敏度與特異性高的 maker。
分子建模預測
采用模式識別與數據挖掘技術有效進行模型的構建,將部分數據拿來做訓練集預測模型,然后部分數據作為測試數據集(獨立樣本)來驗證模型的準確性。目的在于利用實驗數據來篩選出一批靶標基因,并以此構建模型。小樣本數據的建模在于篩選并評判 maker 的穩定性,便于后期實驗驗證;大樣本數據的建模用于進行早期診斷、疾病預測。采用方法分為:線性分類器以及非線性分類器,并利用了 Leave-one-out cross-validation(LOOCV)以及 cross-validated misclassification error rate 的篩選策略找到優選 MARKER。

1、小樣本建模:樣本數在 20 以上;
2、大樣本建模:樣本數在 100 以上;
3、數據類型:表達,甲基化,CNV,SNP 均可。

1、圖片格式:ROC 曲線圖,TIFF 格式;
2、文本文件:樣本的分類情況,靈敏度與特異性,maker 的權重(線性分類器結果)。
-END-

